







天津大学《数据分析与数据挖掘》公开课--学习笔记
- 1.1 数据分析与数据挖掘
- 1.2 分析和挖掘的数据类型
- 1.3 数据分析与数据挖掘方法
- 1.4 数据分析与数据挖掘使用技术
- 1.5 应用场景及存在的问题
- 2.1 数据的属性
- 2.2 数据的基本统计描述
- 2.3 数据的相似性和相异性
- 3.1 数据存在的问题
- 3.2 数据清理
- 3.3 数据集成
- 3.4 数据规约
- 3.5 数据变换与数据离散化
- 4.1 数据仓库的基本概念
- 4.2 数据仓库设计
- 4.3 数据仓库实现
- 4.4 联机分析处理
- 4.5 元数据模型
- 5.1 回归分析
- 5.2 一元线性回归
- 5.3 多元线性回归
- 5.4 多项式回归
- 6.1 频繁模式概述
- 6.2 Apriori算法
- 6.3 FP-growth算法
- 6.4 压缩频繁项集
- 6.5 关联模式评估
- 7.1 分类概述
- 7.2 决策树
- 7.3 朴素贝叶斯分类
- 7.4 惰性学习法
- 7.5 神经网络
- 7.6 分类模型的评估
- 8.1 聚类概述
- 8.2 基于划分的聚类
- 8.3 基于层次的聚类
- 8.4 基于网格的聚类
- 9.1 离群点定义和类型
- 9.2 离群点检测
网址:《数据分析与数据挖掘》–天津大学公开课
链接: https://b23.tv/PJkU28
1.1 数据分析与数据挖掘
数据分析是指采用适当的统计分析方法对收集到的数据进行分析、概括和总结,对数据进行恰当的描述,提取出有用的信息的过程。对决策进行辅助,提供数据的根据,利用表格和列表进行展示。
数据挖掘是指在大量的数据中进行挖掘知识。
1.1.3 知识发现(KDD)的过程
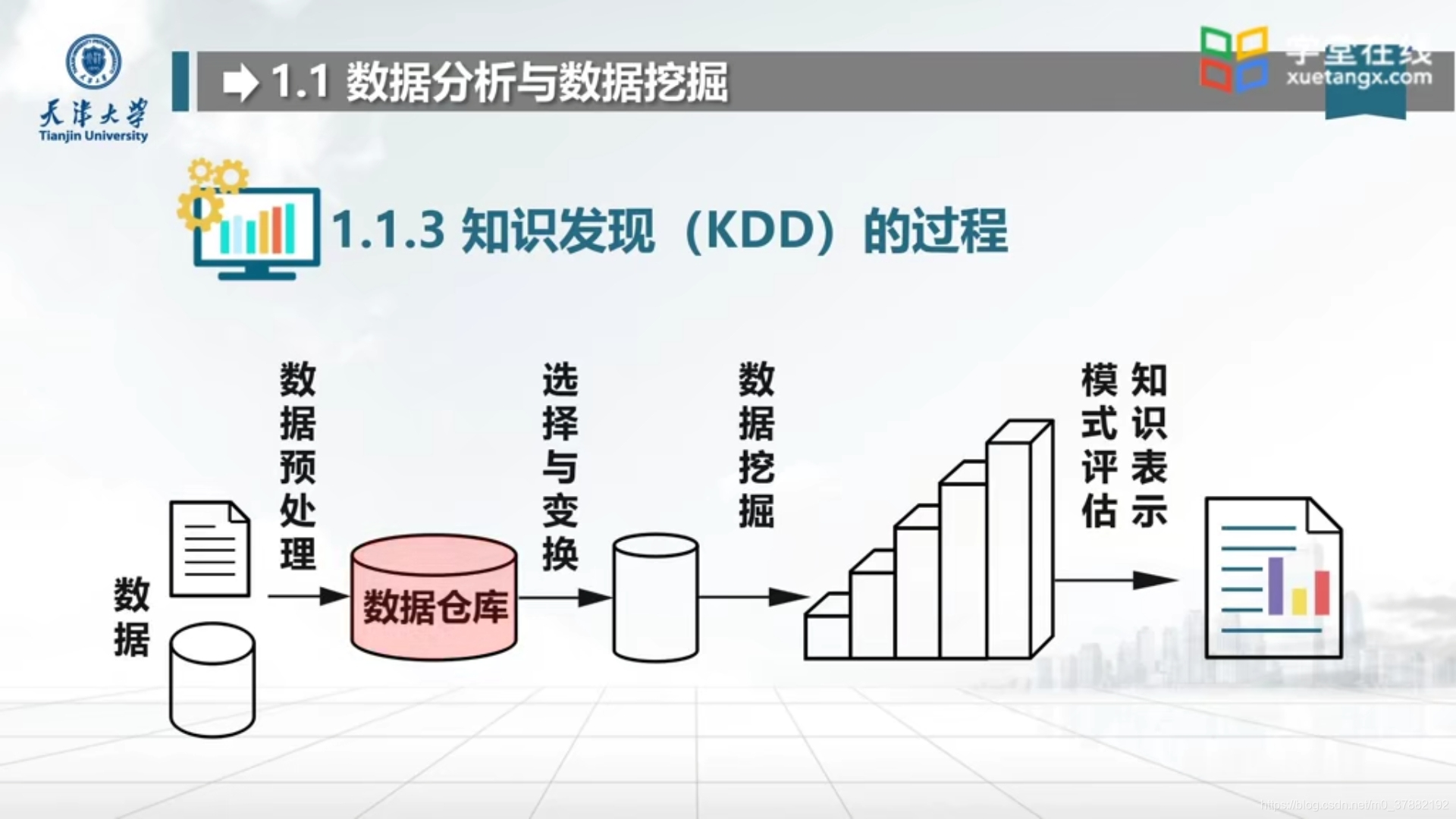
1.1.4 区别

1.1.5 联系

1.2 分析和挖掘的数据类型
1.2.1 数据库数据
关系数据库
SQL
数据库 比较流行的有:MySQL, Oracle, SqlServer
1.2.2 数据仓库数据
数据仓库是一个面向主题的、集成的、随时间变化的、但信息本身相对稳定的数据集合,用于对管理决策过程的支持。
数据仓库 比较流行的有:AWS Redshift, Greenplum, Hive等

1.2.3 事务数据
数据库事务(简称:事务)是数据库管理系统执行过程中的一个逻辑单位,由一个有限的数据库操作序列构成。
一个数据库事务通常包含了一个序列的对数据库的读/写操作。它的存在包含有以下两个目的:
为数据库操作序列提供了一个从失败中恢复到正常状态的方法,同时提供了数据库即使在异常状态下仍能保持一致性的方法。
当多个应用程序在并发访问数据库时,可以在这些应用程序之间提供一个隔离方法,以防止彼此的操作互相干扰。
当事务被提交给了DBMS(数据库管理系统),则DBMS(数据库管理系统)需要确保该事务中的所有操作都成功完成且其结果被永久保存在数据库中,如果事务中有的操作没有成功完成,则事务中的所有操作都需要被回滚,回到事务执行前的状态;同时,该事务对数据库或者其他事务的执行无影响,所有的事务都好像在独立的运行。
但在现实情况下,失败的风险很高。在一个数据库事务的执行过程中,有可能会遇上事务操作失败、数据库系统/操作系统失败,甚至是存储介质失败等情况。这便需要DBMS对一个执行失败的事务执行恢复操作,将其数据库状态恢复到一致状态(数据的一致性得到保证的状态)。为了实现将数据库状态恢复到一致状态的功能,DBMS通常需要维护事务日志以追踪事务中所有影响数据库数据的操作。
1.2.4 数据矩阵
1.2.5 图和网状结构数据
例如社交数据,电商数据,搜索引擎
网页排名算法PageRank
1.3 数据分析与数据挖掘方法
1.3.1 频繁模式
关联与相关性
信用卡分析、购物车分析
1.3.2 分类与回归
1.3.3 聚类分析
聚类:
1.3.4 离群点分析
离群点:
信用卡异常消费
1.4 数据分析与数据挖掘使用技术

1.4.1 统计学方法
1.4.2 机器学习
监督学习
无监督学习
半监督学习
1.4.3 数据库与数据仓库
1.5 应用场景及存在的问题
商务智能、信息识别、搜索引擎
2.1 数据的属性
2.1.1 数据对象
2.1.2 属性

2.1.3 属性类型
2.2 数据的基本统计描述

2.2.1 中心趋势度量
截尾均指:
加权算数平均数:
2.2.2 数据的分散度量
极差:
方差:
2.2.3 数据的图形显示
1、箱图
用来描述最大值、最小值、下四位数、中位数和上四位数的五数概括
2.饼图
3、频率直方图
4、散点图
2.3 数据的相似性和相异性
2.3.1 数据矩阵和相异矩阵
近邻性度量
2.3.2 数值属性的相异性
1、欧几里得距离
2、曼哈顿距离
2.3.3 序数属性的近邻性度量
2.3.4 余弦相似性
余弦相似度
3.1 数据存在的问题
数据不一致
数据缺失
噪声数据
缺失值
3.2 数据清理
3.2.1 空缺值处理
3.2.2 噪声处理
3.3 数据集成
1、实体识别问题
2、冗余问题
数值数据:相关系数及协方差
相关性分析
卡方检验
3.4 数据规约
数据标准化
数据立方体
3.5 数据变换与数据离散化
数据变换:将数据变换成适合数据挖掘的形式
3.5.1 数据泛化
3.5.2 数据规范化
3.5.3 数据变换:属性构造
3.5.4 离散化
分箱法
4.1 数据仓库的基本概念
4.1.1 数据仓库定义和特征
定义:数据仓库,英文名称为Data Warehouse,可简写为DW或DWH。数据仓库,是为企业所有级别的决策制定过程,提供所有类型数据支持的战略集合。它是单个数据存储,出于分析性报告和决策支持目的而创建。 为需要业务智能的企业,提供指导业务流程改进、监视时间、成本、质量以及控制。
特征:集成的、时变性、非易失的、
4.1.2 数据仓库体系结构

4.1.3 数据模型
4.1.4 粒度
4.2 数据仓库设计
面向主题的、集成的、不可更新的
自顶向下,逐步细化
4.2.1 概念模型设计
多维数据模型、
星型模型
雪花模型

事实星座模型
4.2.2 逻辑模型设计
核心基础

4.3 数据仓库实现
SQL实现工具
实例
4.4 联机分析处理
4.4.1 OLAP简介
联机分析处理(OLAP)系统是数据仓库系统最主要的应用,专门设计用于支持复杂的分析操作,侧重对决策人员和高层管理人员的决策支持,可以根据分析人员的要求快速、灵活地进行大数据量的复杂查询处理,并且以一种直观而易懂的形式将查询结果提供给决策人员,以便他们准确掌握企业(公司)的经营状况,了解对象的需求,制定正确的方案。
数据层。实现对企业操作数据的抽取、转换、清洗和汇总,形成信息数据,并存储在企业级的中心信息数据库中。
应用层。通过联机分析处理,甚至是数据挖掘等应用处理,实现对信息数据的分析。
表现层。通过前台分析工具,将查询报表、统计分析、多维联机分析和数据发掘的结论展现在用户面前。
ROLAP、MOLAP、HOLAP
4.4.2 OLAP与OLTP区别
OLTP与OLAP的介绍
数据处理大致可以分成两大类:联机事务处理OLTP(on-line transaction processing)、联机分析处理OLAP(On-Line Analytical Processing)。OLTP是传统的关系型数据库的主要应用,主要是基本的、日常的事务处理,例如银行交易。OLAP是数据仓库系统的主要应用,支持复杂的分析操作,侧重决策支持,并且提供直观易懂的查询结果。
OLTP 系统强调数据库内存效率,强调内存各种指标的命令率,强调绑定变量,强调并发操作;
OLAP 系统则强调数据分析,强调SQL执行市场,强调磁盘I/O,强调分区等。

4.4.3 典型OLAP操作
切片
切块
上卷
下钻
旋转
4.5 元数据模型
4.5.1 元数据内容
元数据库
4.5.2 元数据类型
静态元数据
动态元数据
4.5.3 元数据的作用
元数据

5.1 回归分析
回归分析:
一元线性回归
多元线性回归
多项式回归
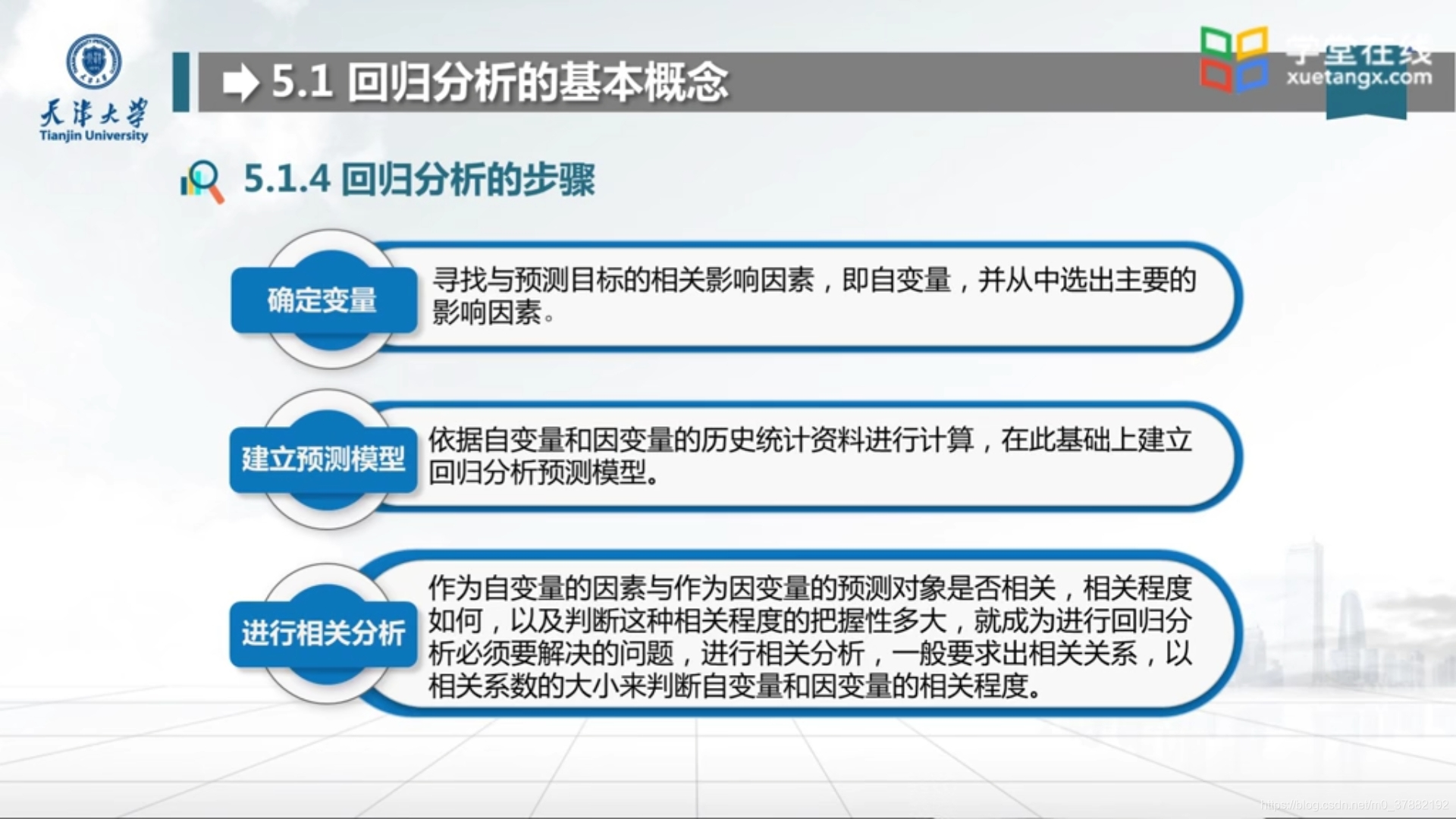
5.1.1 回归分析的步骤
5.2 一元线性回归
5.2.1 回归方程

5.2.2 求解及模型检验
最小二乘法
拟合优度检验
显著性检验
5.3 多元线性回归
5.3.1 回归方程
方程

5.4 多项式回归
5.4.1 回归方程
方程

5.4.2 最小二乘法
5.4.3 拟合优度检验
5.4.4 显著性检验
6.1 频繁模式概述
6.1.1 相关概念
购物车分析、牛奶面包组合
频繁相集
6.1.2 关联规则
关联规则公式
最小支持度
置信度
最小置信度
强关联规则
6.1.3 先验原理
6.2 Apriori算法
6.2.1 关联规则挖掘的方法
穷举法
6.2.2 Apriori算法
Apriori算法是常用的用于挖掘出数据关联规则的算法,它用来找出数据值中频繁出现的数据集合,找出这些集合的模式有助于我们做一些决策。比如在常见的超市购物数据集,或者电商的网购数据集中,如果我们找到了频繁出现的数据集,那么对于超市,我们可以优化产品的位置摆放,对于电商,我们可以优化商品所在的仓库位置,达到节约成本,增加经济效益的目的。

第一步:连接
第二步:剪枝
第三步:计算支持度
本文基于该样例的数据编写Python代码实现Apriori算法。代码需要注意如下两点:
由于Apriori算法假定项集中的项是按字典序排序的,而集合本身是无序的,所以我们在必要时需要进行set和list的转换;
由于要使用字典(support_data)记录项集的支持度,需要用项集作为key,而可变集合无法作为字典的key,因此在合适时机应将项集转为固定集合frozenset。
// An highlighted block
"""
# Python 2.7
# Filename: apriori.py
# Author: llhthinker
# Email: hangliu56[AT]gmail[DOT]com
# Blog: http://www.cnblogs.com/llhthinker/p/6719779.html
# Date: 2017-04-16
"""
def load_data_set():
"""
Load a sample data set (From Data Mining: Concepts and Techniques, 3th Edition)
Returns:
A data set: A list of transactions. Each transaction contains several items.
"""
data_set = [['l1', 'l2', 'l5'], ['l2' 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章















 6823
6823











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









